As we all know that Machine Learning especially Deep Learning with Neural Network has become one of the top trending tech topics in these days. I was trying to get my head around machine learning and AI but I found it does have a steep learning curve for anyone new to this domain. I recently completed an online course Machine Learning on Coursera just to prepare myself for those formulas, algorithms and tech jargons that might come up in machine learning. By the way, this is a really AWESOME course on machine learning. Professor Ng is very knowledgeable and he explained the algorithms very well. I highly recommend any newbies like me to take this course to learn some fundamental concepts and algorithms on machine learning. The coding assignments were done in Matlab/Octave and they helped me understand the algorithms like Linear Regression, Logistic Regression and Neural Networks. That is really good for prototyping but in the real world, we use other programming languages like Python. Tensorflow is one of the most popular open source machine learning libraries in the market and it certainly looks very interesting to me. I was thinking how I can use what I learnt from the course and put them in action with Tensorflow. So here is my hello world with Tensorflow with the help from Keras.
Sometimes it is a bit tricky to get everything set up like setting up libraries and dependencies, although there are package management tools, like pip for Python. Recently I found Colab by Google, which is a super easy way to try out Tensorflow and Keras. It requires no set up at all and you code right in the browser. So Colab is basically a Jupyter notebook hosted by Google and free to use. Google also allows you to use their GPU for hardware acceleration FOR FREE. It is just part of your normal Google Drive. To create a Colab file, just go to your Google Drive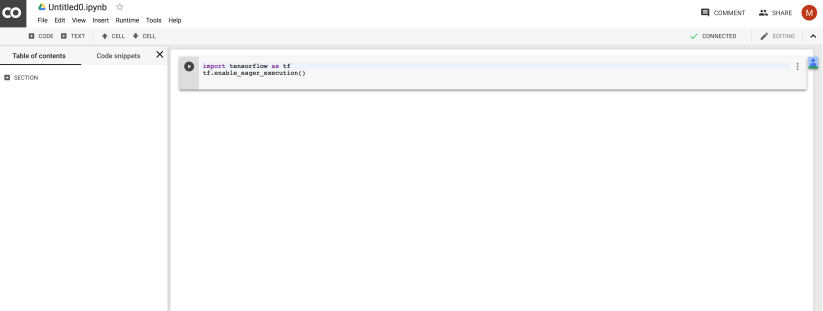 , click New and select More.
, click New and select More.
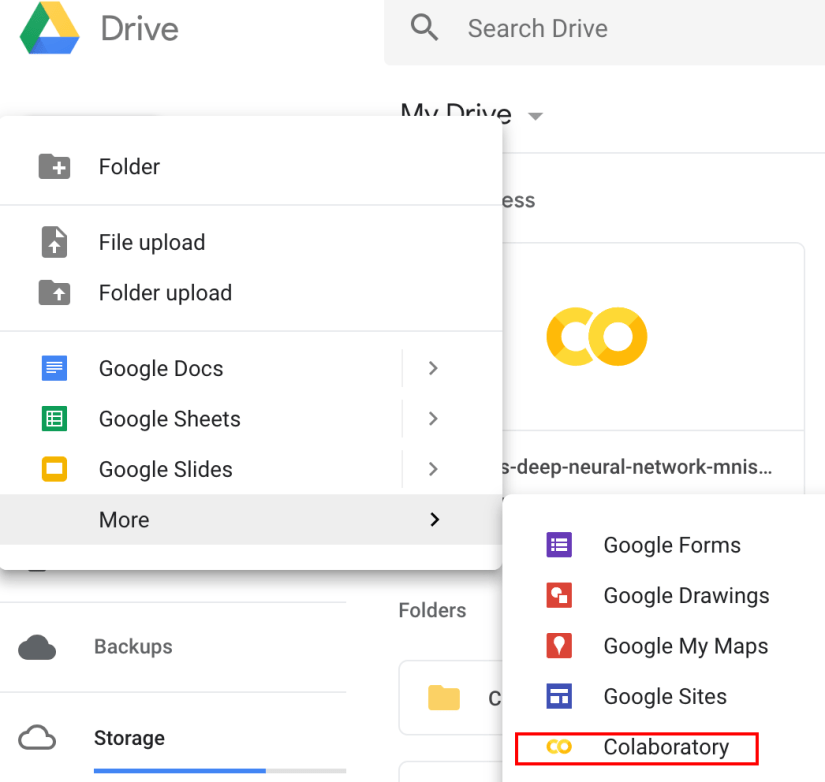
Select Colaboratory and it will open the Jupyter notebook in Google Colab. You will see something like this
Google offers Python 2 and Python 3 runtimes with GPU accelerator option.
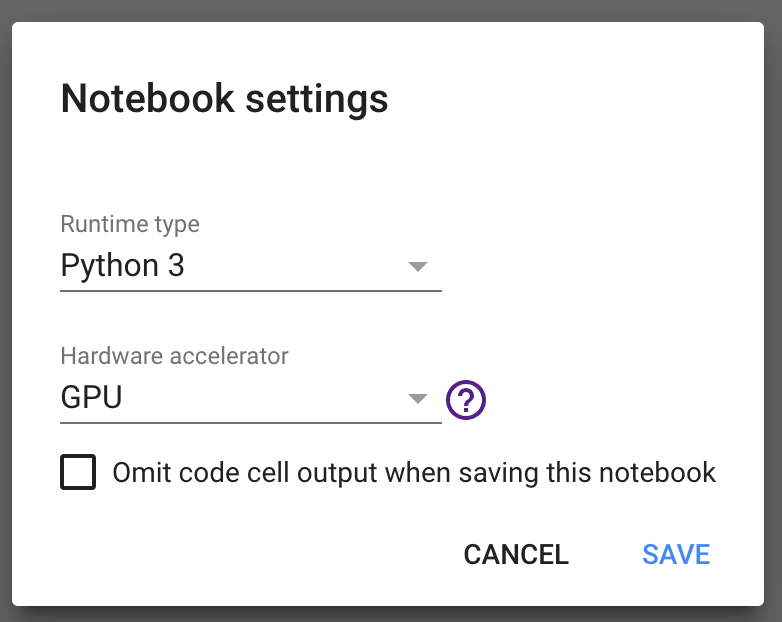
So that looks pretty good. Once the option is saved, it will connect you to one of the VM running on Google Cloud Platform (GCP) and you can run the Python code directly in browser just like running the Jupyter notebook on your local computer. So for trying out Tensorflow, it is perfect as I can skip the installation and start coding straight away.
Just like every Javascript framework has a Todo list app, training a classifier for recognising handwritten digits with the famous MNIST dataset seems to be the hello world example in many machine learning tutorials. In the machine learning course I did, one of the assignment was to do the same thing in Matlab/Octave. So I want to see if I can do the same thing in Python with Keras and Tensorflow. Why Keras? Because I am a newbie and “Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.” according to keras.io. So it should be easier to get started with Tensorflow via Keras at least I hope. In fact, I think it is difficult to use even Keras for anyone without at least some machine learning knowledge. So I checked their docs and here is the code for the classifier with Neural Network. I can see the concepts I learnt from the course started to make sense to me in a totally differently language and framework.
Here I just used the algorithms I learnt from the course.
import numpy as np
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import SGD #Stochastic gradient descent optimizer.5y
batch_size = 128
#10 numbers 0 to 9
num_classes = 10
#iterations for training with the training set.
epochs = 30
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#Convert the image pixils 28X28 to a single vector 784 so a training set
#becomes a matrix. This is using numpy.reshape
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
#Casting the number into float
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
print('The first label from the traing set: ', y_train[0])
#Compress the greyscale level from 0-225 to 0-1
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('The first label in the training set is converted to ', y_train[0])
#Create a model which contains mutliple layers
model = Sequential()
#Add a layer type Dense with 512 output units for the hidden layer
#Because this is the input layer, we need to tell Keras what
#the input data looks like in dimension
#in this case, it is just a single dimension array with 784 units mapped to all
#pixils in a 28X28 grey scale
model.add(Dense(512, activation='sigmoid', input_shape=(784,)))
#According to the doc, dropout is used for preventing overfitting so it is
#a regularisation process. It is easier in Keras than in Matlab
model.add(Dropout(0.2))
#Sigmoid function is used here, but it is said to use Relu function to have a
#better performance. Sigmoid is a bit classic and old school feels like.
model.add(Dense(512, activation='sigmoid'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='sigmoid'))
model.summary()
# Setting up the model for traing by defining the cost function which for is the loss param
# optimiser which is how we use to find the minmal of the cost function
# I use Stochastic gradient descent here as that is what I learnt from the course but there are more advanced optimisers
# in Keras like RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=SGD(),
metrics=['accuracy'])#It looks like accuracy is the one we normally use
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
#Like what I learnt from the course, we use training set and test set for training and
#evaluating the performance
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
After running the script, I got this log and result in the output block.
The first label from the traing set: 5
60000 train samples
10000 test samples
The first label in the training set is converted to [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_25 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_17 (Dropout) (None, 512) 0
_________________________________________________________________
dense_26 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_18 (Dropout) (None, 512) 0
_________________________________________________________________
dense_27 (Dense) (None, 10) 5130
=================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
_________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/30
60000/60000 [==============================] - 3s 52us/step - loss: 2.3062 - acc: 0.1087 - val_loss: 2.2941 - val_acc: 0.1135
Epoch 2/30
23936/60000 [==========>...................] - ETA: 1s - loss: 2.2998 - acc: 0.1191
60000/60000 [==============================] - 3s 49us/step - loss: 2.2969 - acc: 0.1226 - val_loss: 2.2879 - val_acc: 0.1135
Epoch 3/30
60000/60000 [==============================] - 3s 49us/step - loss: 2.2894 - acc: 0.1313 - val_loss: 2.2773 - val_acc: 0.1569
Epoch 4/30
60000/60000 [==============================] - 3s 49us/step - loss: 2.2795 - acc: 0.1451 - val_loss: 2.2554 - val_acc: 0.2048
Epoch 5/30
60000/60000 [==============================] - 3s 49us/step - loss: 2.2550 - acc: 0.1712 - val_loss: 2.2058 - val_acc: 0.4482
Epoch 6/30
60000/60000 [==============================] - 3s 49us/step - loss: 2.2029 - acc: 0.2153 - val_loss: 2.1159 - val_acc: 0.5968
Epoch 7/30
4864/60000 [=>............................] - ETA: 2s - loss: 2.1671 - acc: 0.2336
60000/60000 [==============================] - 3s 49us/step - loss: 2.1094 - acc: 0.2820 - val_loss: 1.9845 - val_acc: 0.6368
Epoch 8/30
60000/60000 [==============================] - 3s 48us/step - loss: 1.9695 - acc: 0.3682 - val_loss: 1.8058 - val_acc: 0.7024
Epoch 9/30
60000/60000 [==============================] - 3s 49us/step - loss: 1.7870 - acc: 0.4544 - val_loss: 1.5833 - val_acc: 0.7046
Epoch 10/30
60000/60000 [==============================] - 3s 49us/step - loss: 1.5744 - acc: 0.5290 - val_loss: 1.3656 - val_acc: 0.7258
Epoch 11/30
60000/60000 [==============================] - 3s 49us/step - loss: 1.3818 - acc: 0.5858 - val_loss: 1.1826 - val_acc: 0.7416
Epoch 12/30
3584/60000 [>.............................] - ETA: 2s - loss: 1.2627 - acc: 0.6328
60000/60000 [==============================] - 3s 48us/step - loss: 1.2214 - acc: 0.6299 - val_loss: 1.0354 - val_acc: 0.7741
Epoch 13/30
60000/60000 [==============================] - 3s 48us/step - loss: 1.0944 - acc: 0.6687 - val_loss: 0.9224 - val_acc: 0.7965
Epoch 14/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.9983 - acc: 0.6954 - val_loss: 0.8352 - val_acc: 0.7980
Epoch 15/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.9155 - acc: 0.7201 - val_loss: 0.7651 - val_acc: 0.8133
Epoch 16/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.8550 - acc: 0.7371 - val_loss: 0.7075 - val_acc: 0.8224
Epoch 17/30
4736/60000 [=>............................] - ETA: 2s - loss: 0.8116 - acc: 0.7508
60000/60000 [==============================] - 3s 49us/step - loss: 0.8023 - acc: 0.7538 - val_loss: 0.6639 - val_acc: 0.8247
Epoch 18/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.7575 - acc: 0.7667 - val_loss: 0.6239 - val_acc: 0.8366
Epoch 19/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.7232 - acc: 0.7761 - val_loss: 0.5921 - val_acc: 0.8411
Epoch 20/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.6915 - acc: 0.7866 - val_loss: 0.5657 - val_acc: 0.8489
Epoch 21/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.6644 - acc: 0.7937 - val_loss: 0.5419 - val_acc: 0.8541
Epoch 22/30
128/60000 [..............................] - ETA: 4s - loss: 0.5881 - acc: 0.7969
60000/60000 [==============================] - 3s 49us/step - loss: 0.6418 - acc: 0.8007 - val_loss: 0.5228 - val_acc: 0.8567
Epoch 23/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.6223 - acc: 0.8067 - val_loss: 0.5058 - val_acc: 0.8624
Epoch 24/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.6040 - acc: 0.8147 - val_loss: 0.4905 - val_acc: 0.8641
Epoch 25/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.5913 - acc: 0.8157 - val_loss: 0.4766 - val_acc: 0.8696
Epoch 26/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.5756 - acc: 0.8225 - val_loss: 0.4643 - val_acc: 0.8720
Epoch 27/30
3712/60000 [>.............................] - ETA: 2s - loss: 0.5573 - acc: 0.8279
60000/60000 [==============================] - 3s 48us/step - loss: 0.5618 - acc: 0.8278 - val_loss: 0.4542 - val_acc: 0.8740
Epoch 28/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.5508 - acc: 0.8291 - val_loss: 0.4461 - val_acc: 0.8743
Epoch 29/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.5367 - acc: 0.8364 - val_loss: 0.4343 - val_acc: 0.8789
Epoch 30/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.5298 - acc: 0.8371 - val_loss: 0.4262 - val_acc: 0.8805
Test loss: 0.4261756734609604
Test accuracy: 0.8805
I can see the cost function/loss was reducing as the iteration when and finally achieved 88.9% accuracy. The result is not too bad but it is not good enough. I think that is to do with the performance of different activation functions and optimiser functions. Increasing the epochs to a bigger number with more iteration it might help with the accuracy.
Accordingly to this interesting article,
ReLU (Rectified Linear Units) have recently become an alternative activation function to the sigmoid function in neural networks.
ReLUs overfit more easily than sigmoids, this makes them a natural fit for dropout which is a technique to avoid overfitting. ReLUs also train faster than sigmoids due to less numerical computation. ReLUs also don’t suffer from the vanishing gradient problem.
Interestingly, if I change the activation function to use ‘ReLu’ (Rectified Linear Unit) function, with SGD as the optimiser, the result is pretty bad about 20%. Initially I thought ReLu does not work quite well with SGD but then it turned out that I shouldn’t use ReLu in the output layer while Sigmoid function still works in the output layer. So when I change the activation function in the output layer to use ‘softmax‘, with the same optimiser SGD and same iteration/epochs set to 30, the performance increased to 96.5%.
Updated code here,
import numpy as np
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import SGD,RMSprop #Stochastic gradient descent optimizer.5y
batch_size = 128
#10 numbers 0 to 9
num_classes = 10
#iterations for training with the training set.
epochs = 30
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#Convert the image pixils 28X28 to a single vector 784 so a training set
#becomes a matrix. This is using numpy.reshape
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
#Casting the number into float
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
print('The first label from the traing set: ', y_train[0])
#Compress the greyscale level from 0-225 to 0-1
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('The first label in the training set is converted to ', y_train[0])
#Create a model which contains mutliple layers
model = Sequential()
#Add a layer type Dense with 512 output units for the hidden layer
#Because this is the input layer, we need to tell Keras what
#the input data looks like in dimension
#in this case, it is just a single dimension array with 784 units mapped to all
#pixils in a 28X28 grey scale
model.add(Dense(512, activation='relu', input_shape=(784,)))
#According to the doc, dropout is used for preventing overfitting so it is
#a regularisation process. It is easier in Keras than in Matlab
model.add(Dropout(0.2))
#Sigmoid function is used here, but it is said to use Relu function to have a
#better performance. Sigmoid is a bit classic and old school feels like.
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
# Setting up the model for traing by defining the cost function which for is the loss param
# optimiser which is how we use to find the minmal of the cost function
# I use Stochastic gradient descent here as that is what I learnt from the course but there are more advanced optimisers
# in Keras like RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=SGD(),
metrics=['accuracy'])#It looks like accuracy is the one we normally use
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
#Like what I learnt from the course, we use training set and test set for training and
#evaluating the performance
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
See the result here
The first label from the traing set: 5
60000 train samples
10000 test samples
The first label in the training set is converted to [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_58 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_39 (Dropout) (None, 512) 0
_________________________________________________________________
dense_59 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_40 (Dropout) (None, 512) 0
_________________________________________________________________
dense_60 (Dense) (None, 10) 5130
=================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
_________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/30
60000/60000 [==============================] - 4s 63us/step - loss: 1.2164 - acc: 0.6829 - val_loss: 0.5372 - val_acc: 0.8654
Epoch 2/30
20736/60000 [=========>....................] - ETA: 1s - loss: 0.5865 - acc: 0.8402
60000/60000 [==============================] - 3s 49us/step - loss: 0.5318 - acc: 0.8513 - val_loss: 0.3744 - val_acc: 0.8965
Epoch 3/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.4263 - acc: 0.8780 - val_loss: 0.3227 - val_acc: 0.9099
Epoch 4/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.3745 - acc: 0.8917 - val_loss: 0.2948 - val_acc: 0.9158
Epoch 5/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.3416 - acc: 0.9009 - val_loss: 0.2731 - val_acc: 0.9214
Epoch 6/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.3169 - acc: 0.9075 - val_loss: 0.2551 - val_acc: 0.9275
Epoch 7/30
4736/60000 [=>............................] - ETA: 2s - loss: 0.2925 - acc: 0.9141
60000/60000 [==============================] - 3s 49us/step - loss: 0.2986 - acc: 0.9137 - val_loss: 0.2405 - val_acc: 0.9315
Epoch 8/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.2825 - acc: 0.9181 - val_loss: 0.2277 - val_acc: 0.9346
Epoch 9/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.2670 - acc: 0.9219 - val_loss: 0.2195 - val_acc: 0.9366
Epoch 10/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.2554 - acc: 0.9260 - val_loss: 0.2080 - val_acc: 0.9399
Epoch 11/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.2428 - acc: 0.9299 - val_loss: 0.1988 - val_acc: 0.9423
Epoch 12/30
3584/60000 [>.............................] - ETA: 2s - loss: 0.2280 - acc: 0.9308
60000/60000 [==============================] - 3s 49us/step - loss: 0.2317 - acc: 0.9324 - val_loss: 0.1915 - val_acc: 0.9437
Epoch 13/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.2244 - acc: 0.9349 - val_loss: 0.1843 - val_acc: 0.9457
Epoch 14/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.2149 - acc: 0.9373 - val_loss: 0.1771 - val_acc: 0.9474
Epoch 15/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.2062 - acc: 0.9407 - val_loss: 0.1717 - val_acc: 0.9489
Epoch 16/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.2000 - acc: 0.9417 - val_loss: 0.1660 - val_acc: 0.9504
Epoch 17/30
3712/60000 [>.............................] - ETA: 2s - loss: 0.1933 - acc: 0.9410
60000/60000 [==============================] - 3s 48us/step - loss: 0.1927 - acc: 0.9442 - val_loss: 0.1603 - val_acc: 0.9511
Epoch 18/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.1875 - acc: 0.9451 - val_loss: 0.1553 - val_acc: 0.9526
Epoch 19/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.1807 - acc: 0.9472 - val_loss: 0.1504 - val_acc: 0.9532
Epoch 20/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.1758 - acc: 0.9486 - val_loss: 0.1463 - val_acc: 0.9551
Epoch 21/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.1690 - acc: 0.9516 - val_loss: 0.1423 - val_acc: 0.9565
Epoch 22/30
3584/60000 [>.............................] - ETA: 2s - loss: 0.1723 - acc: 0.9487
60000/60000 [==============================] - 3s 49us/step - loss: 0.1661 - acc: 0.9511 - val_loss: 0.1394 - val_acc: 0.9571
Epoch 23/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.1617 - acc: 0.9532 - val_loss: 0.1353 - val_acc: 0.9588
Epoch 24/30
60000/60000 [==============================] - 3s 49us/step - loss: 0.1555 - acc: 0.9550 - val_loss: 0.1315 - val_acc: 0.9605
Epoch 25/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.1528 - acc: 0.9553 - val_loss: 0.1295 - val_acc: 0.9606
Epoch 26/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.1494 - acc: 0.9564 - val_loss: 0.1263 - val_acc: 0.9613
Epoch 27/30
4992/60000 [=>............................] - ETA: 2s - loss: 0.1385 - acc: 0.9619
60000/60000 [==============================] - 3s 48us/step - loss: 0.1442 - acc: 0.9586 - val_loss: 0.1239 - val_acc: 0.9608
Epoch 28/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.1430 - acc: 0.9580 - val_loss: 0.1214 - val_acc: 0.9628
Epoch 29/30
60000/60000 [==============================] - 3s 47us/step - loss: 0.1383 - acc: 0.9596 - val_loss: 0.1185 - val_acc: 0.9639
Epoch 30/30
60000/60000 [==============================] - 3s 48us/step - loss: 0.1355 - acc: 0.9602 - val_loss: 0.1161 - val_acc: 0.9652
Test loss: 0.11608425705060363
Test accuracy: 0.9652
It looks pretty good this time, 8% performance gains!!
I had bit of look around and tried different optimiser algorithms. I found in Keras tutorial that if I change the optimiser function from SGD to RMSprop, it gave me 98% accuracy at the end which is better than SGD. So the updated code is
import numpy as np
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import SGD,RMSprop #Stochastic gradient descent optimizer.5y
batch_size = 128
#10 numbers 0 to 9
num_classes = 10
#iterations for training with the training set.
epochs = 30
(x_train, y_train), (x_test, y_test) = mnist.load_data()
#Convert the image pixils 28X28 to a single vector 784 so a training set
#becomes a matrix. This is using numpy.reshape
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
#Casting the number into float
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
print('The first label from the traing set: ', y_train[0])
#Compress the greyscale level from 0-225 to 0-1
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
print('The first label in the training set is converted to ', y_train[0])
#Create a model which contains mutliple layers
model = Sequential()
#Add a layer type Dense with 512 output units for the hidden layer
#Because this is the input layer, we need to tell Keras what
#the input data looks like in dimension
#in this case, it is just a single dimension array with 784 units mapped to all
#pixils in a 28X28 grey scale
model.add(Dense(512, activation='relu', input_shape=(784,)))
#According to the doc, dropout is used for preventing overfitting so it is
#a regularisation process. It is easier in Keras than in Matlab
model.add(Dropout(0.2))
#Sigmoid function is used here, but it is said to use Relu function to have a
#better performance. Sigmoid is a bit classic and old school feels like.
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
# Setting up the model for traing by defining the cost function which for is the loss param
# optimiser which is how we use to find the minmal of the cost function
# I use Stochastic gradient descent here as that is what I learnt from the course but there are more advanced optimisers
# in Keras like RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])#It looks like accuracy is the one we normally use
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
#Like what I learnt from the course, we use training set and test set for training and
#evaluating the performance
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
The result is here
The first label from the traing set: 5
60000 train samples
10000 test samples
The first label in the training set is converted to [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_64 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_43 (Dropout) (None, 512) 0
_________________________________________________________________
dense_65 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_44 (Dropout) (None, 512) 0
_________________________________________________________________
dense_66 (Dense) (None, 10) 5130
=================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
_________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/30
60000/60000 [==============================] - 4s 68us/step - loss: 0.2462 - acc: 0.9241 - val_loss: 0.1112 - val_acc: 0.9648
Epoch 2/30
12160/60000 [=====>........................] - ETA: 2s - loss: 0.1084 - acc: 0.9682
60000/60000 [==============================] - 3s 55us/step - loss: 0.1030 - acc: 0.9681 - val_loss: 0.0853 - val_acc: 0.9747
Epoch 3/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0754 - acc: 0.9766 - val_loss: 0.0746 - val_acc: 0.9784
Epoch 4/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0599 - acc: 0.9816 - val_loss: 0.0824 - val_acc: 0.9781
Epoch 5/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0515 - acc: 0.9841 - val_loss: 0.0781 - val_acc: 0.9797
Epoch 6/30
47360/60000 [======================>.......] - ETA: 0s - loss: 0.0435 - acc: 0.9872
60000/60000 [==============================] - 3s 55us/step - loss: 0.0440 - acc: 0.9868 - val_loss: 0.0831 - val_acc: 0.9805
Epoch 7/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0381 - acc: 0.9888 - val_loss: 0.0739 - val_acc: 0.9817
Epoch 8/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0348 - acc: 0.9897 - val_loss: 0.0847 - val_acc: 0.9823
Epoch 9/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0325 - acc: 0.9906 - val_loss: 0.0914 - val_acc: 0.9806
Epoch 10/30
51712/60000 [========================>.....] - ETA: 0s - loss: 0.0286 - acc: 0.9923
60000/60000 [==============================] - 3s 55us/step - loss: 0.0288 - acc: 0.9921 - val_loss: 0.0970 - val_acc: 0.9829
Epoch 11/30
60000/60000 [==============================] - 3s 54us/step - loss: 0.0277 - acc: 0.9925 - val_loss: 0.0924 - val_acc: 0.9823
Epoch 12/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0258 - acc: 0.9929 - val_loss: 0.1105 - val_acc: 0.9812
Epoch 13/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0243 - acc: 0.9937 - val_loss: 0.0978 - val_acc: 0.9828
Epoch 14/30
52480/60000 [=========================>....] - ETA: 0s - loss: 0.0228 - acc: 0.9939
60000/60000 [==============================] - 3s 55us/step - loss: 0.0240 - acc: 0.9937 - val_loss: 0.0939 - val_acc: 0.9836
Epoch 15/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0221 - acc: 0.9940 - val_loss: 0.1095 - val_acc: 0.9815
Epoch 16/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0214 - acc: 0.9944 - val_loss: 0.0969 - val_acc: 0.9832
Epoch 17/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0208 - acc: 0.9949 - val_loss: 0.1127 - val_acc: 0.9819
Epoch 18/30
49536/60000 [=======================>......] - ETA: 0s - loss: 0.0211 - acc: 0.9946
60000/60000 [==============================] - 3s 55us/step - loss: 0.0207 - acc: 0.9948 - val_loss: 0.1227 - val_acc: 0.9821
Epoch 19/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0195 - acc: 0.9950 - val_loss: 0.1171 - val_acc: 0.9835
Epoch 20/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0199 - acc: 0.9950 - val_loss: 0.1146 - val_acc: 0.9840
Epoch 21/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0180 - acc: 0.9954 - val_loss: 0.1108 - val_acc: 0.9832
Epoch 22/30
51968/60000 [========================>.....] - ETA: 0s - loss: 0.0172 - acc: 0.9960
60000/60000 [==============================] - 3s 55us/step - loss: 0.0173 - acc: 0.9959 - val_loss: 0.1093 - val_acc: 0.9843
Epoch 23/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0166 - acc: 0.9960 - val_loss: 0.1295 - val_acc: 0.9826
Epoch 24/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0168 - acc: 0.9961 - val_loss: 0.1203 - val_acc: 0.9839
Epoch 25/30
60000/60000 [==============================] - 3s 54us/step - loss: 0.0174 - acc: 0.9958 - val_loss: 0.1079 - val_acc: 0.9842
Epoch 26/30
53504/60000 [=========================>....] - ETA: 0s - loss: 0.0156 - acc: 0.9965
60000/60000 [==============================] - 3s 54us/step - loss: 0.0151 - acc: 0.9967 - val_loss: 0.1106 - val_acc: 0.9855
Epoch 27/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0161 - acc: 0.9964 - val_loss: 0.1195 - val_acc: 0.9847
Epoch 28/30
60000/60000 [==============================] - 3s 54us/step - loss: 0.0167 - acc: 0.9959 - val_loss: 0.1304 - val_acc: 0.9830
Epoch 29/30
60000/60000 [==============================] - 3s 55us/step - loss: 0.0155 - acc: 0.9964 - val_loss: 0.1285 - val_acc: 0.9835
Epoch 30/30
52864/60000 [=========================>....] - ETA: 0s - loss: 0.0152 - acc: 0.9968
60000/60000 [==============================] - 3s 55us/step - loss: 0.0155 - acc: 0.9966 - val_loss: 0.1215 - val_acc: 0.9849
Test loss: 0.12145777981619352
Test accuracy: 0.9849
So this is the hello world in machine learning with Keras and Tensorflow. And Google Colab, it is AWESOME!

